Github Repos for reference
💡 All tools and models used here are exchangeable with other models and libraries.
Purpose of this post:
MCP - Model Context Protocol is relatively new entrant in the world of AI Agents but acquired people’s mindset because of it’s initiative to standardize the interfaces. It became even more important as Anthropic competitors (like Open AI) announced support towards MCP and multiple other tools (like Cursor IDE) immediately embraced the concept by becoming an MCP Client.
I think the power of MCP lays in connecting the definitiveness of APIs (typically exposing structured data) with unstructured LLM chat (like in this case Claude Desktop) to get a much powerful response.
Use case
In this post, we will try to help a highschooler who is trying to gather information on his target schools and majors.
Components
- I created a json file (in place of a real database) that captures various important urls of schools and tag each of the urls with meningful categories. Example below -
{
"school": "TAMU",
"urls": [
{
"url": "https://www.tamu.edu/",
"tags": ["homepage", "overview"]
},
{
"url": "https://www.tamu.edu/admissions/how-to-apply/apply-as-freshman.html",
"tags": ["application", "timeline"]
},
{
"url": "https://www.tamu.edu/academics/colleges-schools/college-of-engineering.html",
"tags": ["engineering", "overview"]
I built an API that exposes this data over HTTP which will be used for one of the MCP servers (get_schools)
I crawled all the urls and created a Contextual RAG pipeline which also exposes an API that will be used by the other MCP servers (ask_rag).
💡 In case needed feel free to refer to my post on Contextual RAG .
I created MCP Servers in a separate python project and configured those to Claude Desktop (a MCP client) so that claude can actually use the local tools to query first before sending to anthropic for final response.
Context Diagram
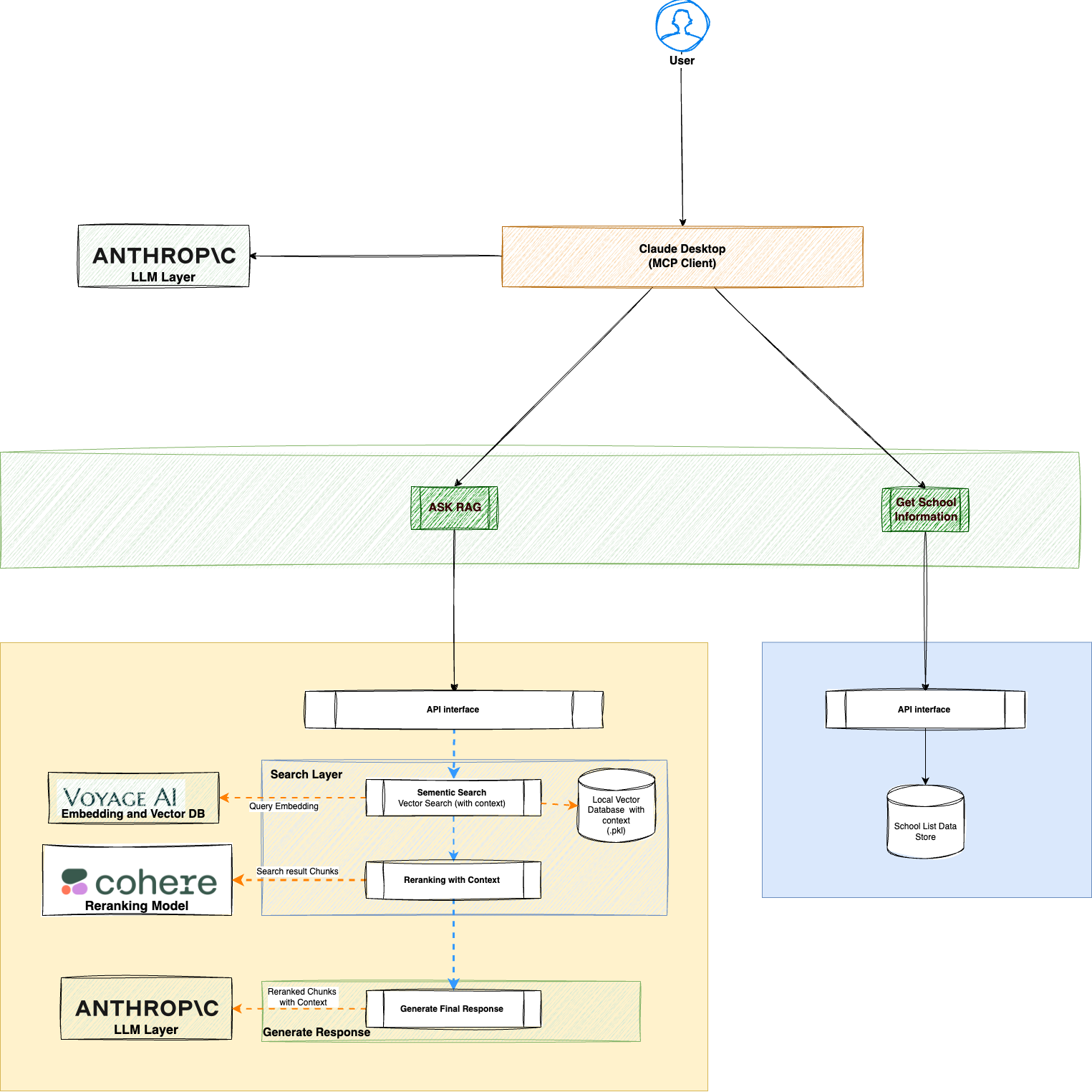
How MCP Works and How this was built?
There are two parts of MCP
- MCP Server: This is the functional piece that the application will expose. There is a list of reference servers available in Anthropic MCP Server Repo. However this is the place where application developers will expose their data capabilities. In this application I built two servers that essentially exposes my data (for illustration purpose)
- Get School Info:Schools Url and categorization information as a NestJS API
- Ask RAG:Contextual RAG pipeline exposed as API that already has following capabilities:
- Pre process the school related urls as follows:
- Chunk them
- Generate context by sending the Chunk with whole document to LLM (in this case anthropic)
- Store locally
- Load the chunks in Vector DB (in this case VoyagerAI)
- Use rerank to narrow down and rank the chunks after similarity/sementic search (use cohere in this case)
- Generate the response and source Urls by sending chunks to LLM (anthropic in this case)
- Finally expose the whole chat capability in an API interface
- Pre process the school related urls as follows:
- MCP Client: I use Claude desktop in this example (and tested with Claude Code and Cursor). However it can be used in any client tool that follows MCP Client standards. Configuration is quite simple as below:
{ "mcpServers": { "get_schools": { "command": "FULL/PATH/TO/UV", "args": [ "--directory", "/FULL/PATH/TO/LOCAL/PROJECT", "run", # command to run "t_schools.py" # file to run ] }, "ask_rag": { "command": "/FULL/PATH/TO/LOCAL/PROJECT", "args": [ "--directory", "/FULL/PATH/TO/LOCAL/PROJECT", "run", "chat_api.py" ] } } }💡 You may need to provide full path for the commands to run - relative path may not work
Once properly setup these tools start showing up in Claude desktop (you will have to quite and restart claude desktop). From that point onwards as you ask questions to Claude, it will look into tools first, ask you permission before using the tool and then finally generate a comprehensive answer using LLM.
As seen in the screenshot, claude desktop first uses ask_rag server to get chunks and then also uses get_schools. Then it sends to LLM but also negotiates MCP servers multiple times.
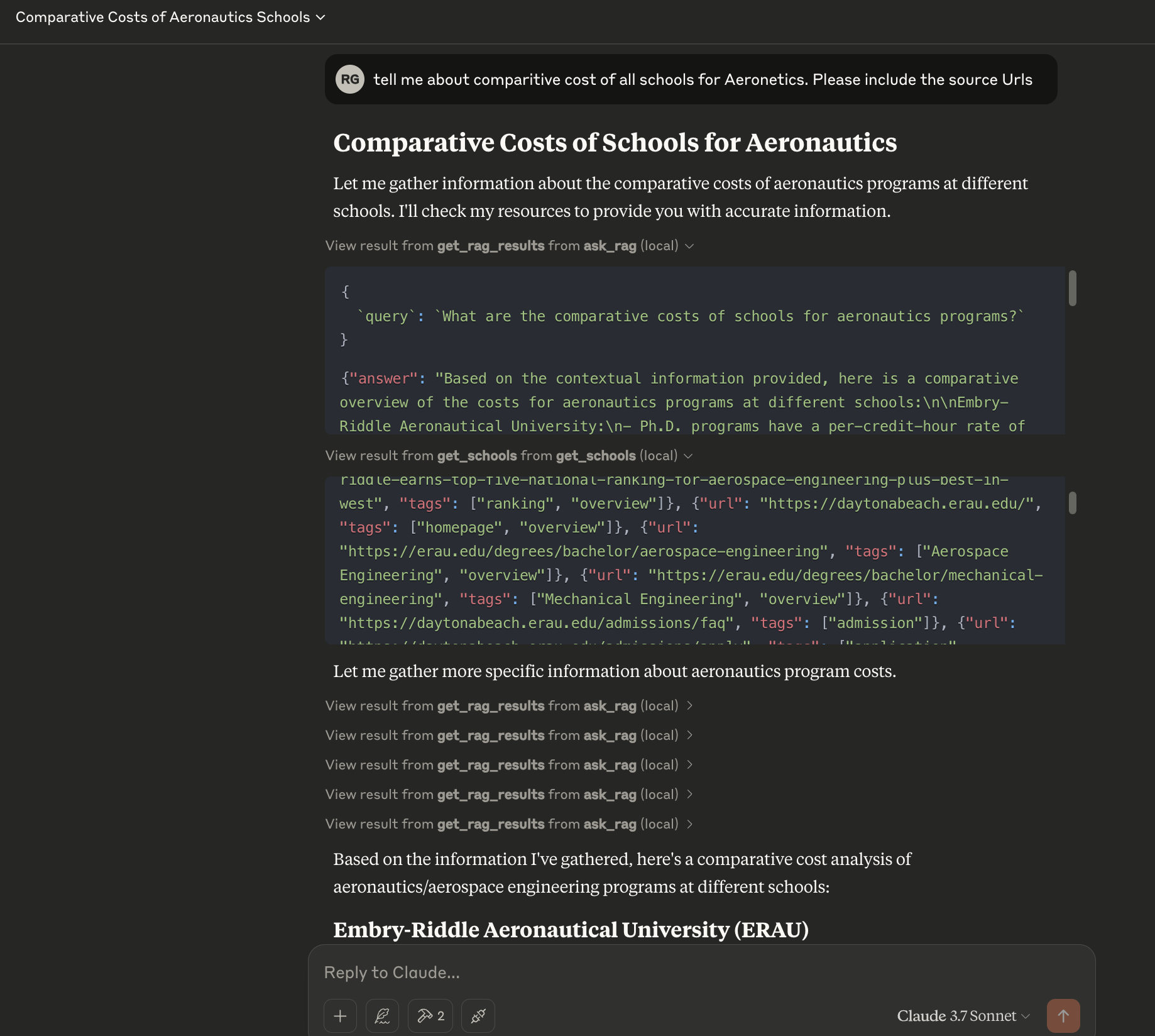
Finally it actually gives a much more comprehensive response that makes an effort to use all fragments of information coming out of the tools to summarize in a usable form.
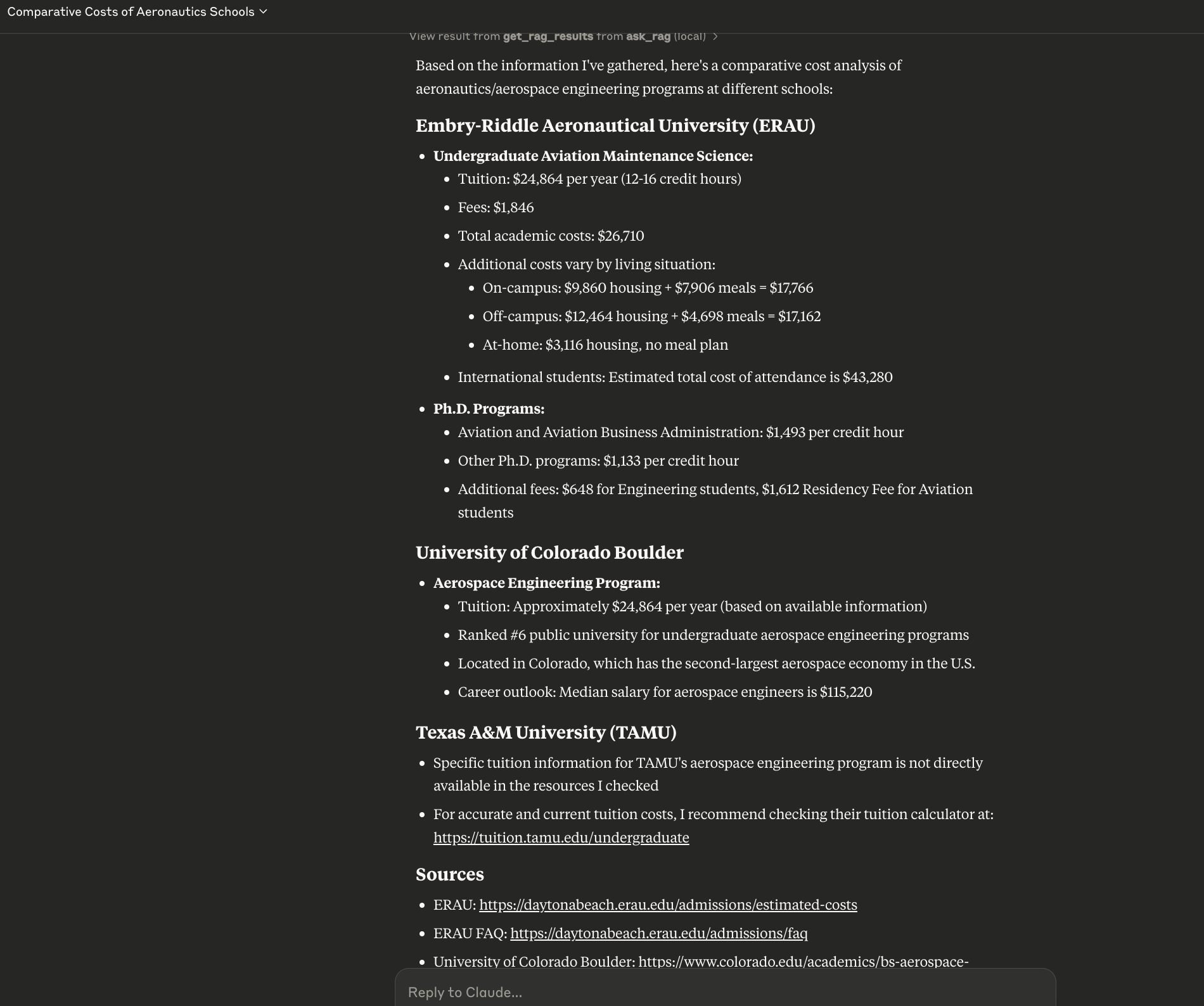
💡 Important thing to note here is - the information is coming from the RAG not from LLM. This reduces/avoids hallucination significantly